Python代码风格和美化工具

| 出品方 | 代码风格 | 美化工具 |
|---|---|---|
| Python | PEP8 网友译, 本人译 | Black |
| Google Python Style 网友译 | YAPF |
代码风格(Code Style)与编码规范还是有些差异,我以为:
- 代码风格 主要关注代码排版、一致性、易读性 —— 至美
- 编码规范 概念更宏观,范畴更广泛,包括设计理念、性能优化、代码风格 —— 至真、至善、至美
PSF & PEP
PSF(Python Software Foundation),Python 的官方组织。PSF 提供的文档包括:
- Python Doc (API 手册)
- Guide:
- 资源列表:PSF 收集的各种语言的学习、开发资源
- PEP :Python Enhancement Proposals、Python 增强建议书
PEP 是 PSF 写出、收纳、提供给社区参考使用、包含新特性、规范性等内容的说明文档。
PEP 在github上撰写、管理,自动编译 html、同步到网站上,从 2000 年开始创建,至今(2019.5)仍非常活跃,如果是 python 的 developer,建议 star 或 watch 它,实时跟踪。
PEP 分了 8 类:核心类、已提交、已接收、讨论中、讨论完、归档、拒绝、废弃。
- 有些 pep 很庞大,如:pep8(python 代码风格);也有些很简短,如:pep7(c 代码风格)
- 有些 pep 很一本正经,如:pep569(Python 3.8 Release Schedule);有些也很搞怪,如:pep20(Zen of Python,20 条禅学)
要贡献 PEP,需要参考 pep12 的模板来写,并且 PEP 不是用 markdown 写的,而是 ReStructuredText,也是标记(markup)语言,语法比 markdown 稍复杂一点点,这里有一些语法说明:
普通 Python 开发人员必读的 PEP 有:
- 代码风格
- 文档规范
PEP8 Style Guide for Python Code
核心类 pep 是 PEPs of PEPs,目前只有 9 个,PEP8 位列其中,内容是 Python 的代码风格(Code Style),Python 开发人员必读文档之一。
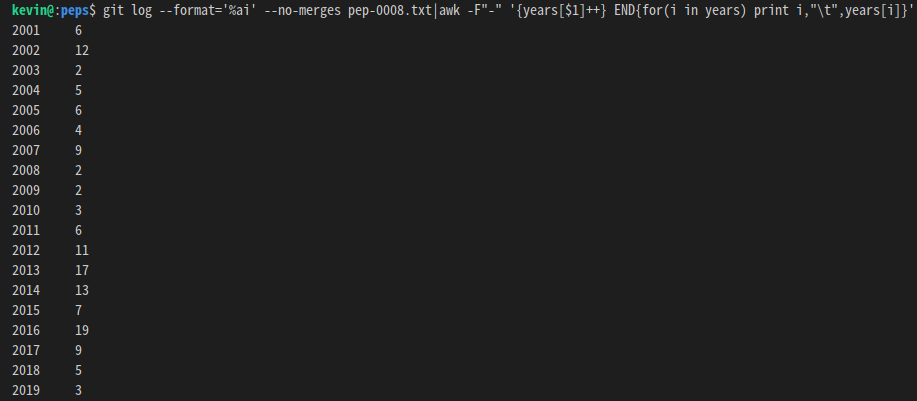
PEP8 从 2001 年创建,至今有 141 次提交:
![]()
修改(提交)集中在 2002、 2012~2016 年,2019 已相对稳定:
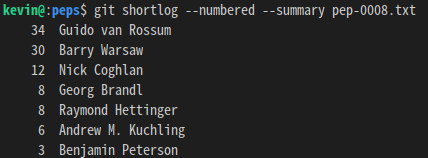
参与撰写的人不少,但 top3 都是 python 官方的人:
PEP8 极简版
PEP8 有网友翻译:python 代码风格指南(PEP8 中文版),目前最后更新时间 2018.8。
下面我来根据 2019.5 的 PEP8,整理一份极简版,相比上面的网友翻译,增补了:
- Module 级 dunder
- 尾随逗号
极简版正文:
写“可读的代码”
代码的使用频率上看:读取远大于编写,所以一定要写“可读的代码”
每级缩进 4 空格,不允许 tab 和空格混用
入参和 if 分开讨论
# 函数定义的入参比函数名多1级缩进
def long_function_name(
var_one, var_two, var_three,
var_four):
print(var_one)
# 函数调用的入参可对准左括号 or 悬挂缩进1级
foo = long_function_name(var_one, var_two,
var_three, var_four)
foo = long_function_name(
var_one, var_two,
var_three, var_four)
# if条件语句跨行时缩进:加1级即可
if (this_is_one_thing
and that_is_another_thing):
do_something()
最大行宽79 字符,文本块 72 字符,极限 99 字符
- 以前通常在二元运算符(+-*/ and or...)之后续行
- 现在推荐在二元运算符之前续行
income = (gross_wages
+ taxable_interest
+ (dividends - qualified_dividends)
- ira_deduction
- student_loan_interest)
空行要尽量节约使用
- 顶层函数和 Class 之间可以用 2 个空行
- Class 内的方法之间用 1 个空行
源文件字符编码尽量使用 utf-8
- ASCII 和 utf-8 的源文件不需要“编码声明”
- 标准库更严格:符号必须用 ASCII,其他尽量英文字母
- 注释 or 字符串可以用非 ASCII 字符
\x \u \U \N
: str1='\xE4'
: print(str1)
ä
: str2 = '\u4f60\u597d'
: print(str2)
你好
: str3='你好'.encode('unicode-escape')
: print(str3)
b'\\u4f60\\u597d'
import 每行导入 1 个模块
- import 要有顺序:标准库进口,第三方库,本地库 —— 各组的导入之间要有空行
- 禁止使用通配符导入
from xxx import *
Module 级 dunder 必须在__future__之后,其他 import 之前
- dunder (double underscore, 双下划线)
- 最早 python 对
__all__这种符号称为魔法变量、魔法函数,后来为了破除迷信,称为 double underscore method,但太长了,被简称为 dunder symbol、dunder method…… - Module 级的 dunder 有 2 个约束
- 必须在
from __future__ import ...后面 - 必须在其他 import 前面
- 必须在
from __future__ import barry_as_FLUFL
__all__ = ['a', 'b', 'c']
__version__ = '0.1'
__author__ = 'Cardinal Biggles'
import os
import sys
python 字符串的单引号与双引号等效
空格的讲究有很多
- 括号(圆括号、方括号)内避免空格
- 左括号之前避免空格
- 逗号、冒号、分号之前避免空格,之后可有
- 索引中的冒号前后都要避免空格
- 赋值等操作符前后不能因为对齐而添加多个空格
- 二元运算符两边放置一个空格
- 优先级高的运算符或操作符的前后不建议有空格
- 关键字参数和默认值参数的前后不要加空格
# 错误示范:
spam( ham[ 1 ], { eggs: 2 } ) # 括号里面太多空格
ham[1: 9], ham[1 :9], ham[1:9 :3] # 索引冒号前后不应有空格
long_variable = 3
x = 1 # 不能为了对齐等号而加空格
i=i+1 # =和+左右都要有空格
submitted +=1 # += 右边没有空格
x = x * 2 - 1 # *优先级高,左右不应有空格
def complex(real, imag = 0.0): # 默认参数的=左右不能有空格
return magic(r = real, i = imag)
function annotations =前后有空格,:和->前无后有
python3 中引入了 function annotations,它是一种注释性质的语法,用于声明入参的类型和默认值。
- 2006 年的 PEP3107 首先定义了 Function Annotations
- 2014 年的 PEP484 补充和修订了 Function Annotations
- 2016 年,又发展出了 PEP526,定义了 Variable Annotations
import enforce
@enforce.runtime_validation
def add_int(a: int, b: int = 0)-> int:
return a + b
print(add_int.__annotations__)
- 表明入参 a 是 int 型,b 是 int 型且默认值 0,返回值 int 型
func.__annotations__返回函数入参注释信息- 有@enforce 则强制类型检查,不匹配报错;不加 @enforce 则只做告警,不报错
- function annotations 的代码风格要求
- =前后要有空格
- 冒号和"->"的前无,后有。
def add_int(a:int, b: int=0) -> int: # 错误示范,有3处错误
def add_int(a: int, b: int = 0)-> int: # 正确示范
尾随逗号在 Tuple 中重要,List 中无效;分行中有利,单行中冗余
尾随逗号(Trailing Commas)
FILES0 = ('setup.cfg') # 0
FILES1 = ('setup.cfg',) # 1
FILES2 = 'setup.cfg', # 2
FILES3 = ['setup.cfg', 'tox.ini'] # 3
FILES4 = ['setup.cfg', 'tox.ini', ] # 4
FILES5 = [ # 5
'setup.cfg',
'tox.ini',
]
- 类型:0 是 str,1/2 是 tuple,3/4 是 list
: print(type(FILES0),type(FILES1),type(FILES2),type(FILES3),type(FILES4))
<class 'str'> <class 'tuple'> <class 'tuple'> <class 'list'> <class 'list'>
- 1==2 —— Tuple 中尾随逗号是重要的
In [42]: FILES1==FILES2
Out[42]: True
- 3==4==5 —— List 中尾随逗号是无效的
In [43]: FILES3==FILES4==FILES5
Out[43]: True
- 5 中每行增加尾随逗号是有意义的,可以减少新增行时的工作量
- 4 中单行增加尾随逗号是没有意义的。
注释书写规范参考 PEP257
- 与代码自相矛盾的注释比没注释更差。修改代码时要优先更新注释!
- 注释段落中的每个句子应该以句号+2 个空格结束。
- 文档化注释(或称为:可生成文档的注释)需遵守 PEP257
- 将来有空可以单讲一篇,先挖个坑吧
命名:可用一张表格说清
程序猿常见的命名风格多样:
| Naming Styles | 举例 | 使用场景 | 备注 |
|---|---|---|---|
| 单个小写字母 | b | 变量名 | 避免使用小写 l(易与 1,I 混) |
| 单个大写字母 | B | 变量名 | 避免使用大写 O(易与 0 混)、I |
| 小写串 | lowercase | 变量名,包名,模块名 | 模块名对应文件名,有线系统文件名不区分大小写 |
| 带下划线的小写 | lower_case_with_underscores | 函数名,类的公开方法 | |
| 大写串 | UPPERCASE | 常量 | 通常在模块级别定义 |
| 带下划线的大写串 | UPPER_CASE_WITH_UNDERSCORES | 常量 | 同上 |
| 驼峰命名法 首字母大写的单词串 | CapitalizedWords(CapWords) | Class 名 | 专有名次缩写可全大写,如 HTTP |
| 匈牙利命名法 混合大小写,首单词小写 | mixedCase | python 抵制 极少特殊情况下用于函数名 | |
| 带下划线,首字母大写 | Capitalized_Words_With_Underscores | python 抵制,丑陋 | |
| 短前缀分组+匈牙利或驼峰 | bsp_getPower | python 抵制,与 C 划清界限 | |
| 单前置下划线 | _single_leading_underscore | 用于不想被外部使用的全局变量 或局部变量 类的非公开方法和实例变量 | 弱内部使用 weak "internal use" |
| 单后置下划线 | singletrailing_underscore | def func(class_='name') | 用于避免与 Python 关键词的冲突 |
| 双前置下划线 | __double_leading_underscore | 类 Foo 中的__bar会变成_Foo__bar | 当用于命名类属性,会触发名字重整 |
| 双前后下划线 | __dunder_func__ | Dunder(魔法)函数 | 不要自己发明这样的名字 |
- Python 中没有属性是真正私有的,所以没有 private 方法。
- 简单的公开数据属性,最好只公开属性名,没有复杂的访问/修改方法,python 的 Property 提供了很好的封装方法。
- 为了更好地支持内省,模块要在
__all__属性列出公共 API。 - 如果命名空间(包、模块或类)是内部的,里面的接口也是内部的。
编程建议
下面就不单纯是格式(format)的问题了,而是有利于程序运行的内容。
- 要明白自己在用哪个 python 解释器
- 官方整理出来好几十个
- CPython: https://www.python.org/downloads/ 官网下载的既是
- CPython 衍生的 stacklessPython, wpython, microPython...
- PyPy:Python in Python
- Jython:Python in Java
- IronPython:Python in C#
- ActivePython
- WinPython
- CPython 及其衍生底层是用 C 实现的,所以对 C/Python API 都有完美支持。非 C 语言实现的编译器虽然某些操作会快一些,但最大的问题是不支持某些只有 C 接口的库,如:numpy、scipy……
- 不同的编译器之间效率有差别,官方建议你仔细研究、斟酌
- 官方整理出来好几十个
if foo is not None优于if not foo is Noneif foo == None用法错误- 比较排序操作最好实现完整 6 个操作:
__eq__, __ne__, __lt__, __le__, __gt__, __ge__ - 变量赋值不要用 lambda,而要用 def,如:
f = lambda x: 2*x #不推荐 - 空"except:"子句(相当于 except Exception)会捕捉 SystemExit 和 KeyboardInterrupt 异常,难以用 Control-C 中断程序,并可掩盖其他问题。只适用于 2 种情况
- 打印出或记录了 traceback,至少让用户将知道已发生错误
- 代码需要做一些清理工作,并用 raise 转发了异常,try...finally 可以捕捉到它
- 本地资源用 with,使用 with 的资源要有独立的 enter、exit 方法
- 函数或者方法在没有返回时要明确返回 None
def foo(x):
if x < 0:
return # No!请 return None
return math.sqrt(x)
- 使用字符串方法而不是 string 模块
- Python 不支持单字符类型,单字符在 Python 中也是作为一个字符串
# 字符串方法
>>> type(str) # str是python关键字
<class 'type'>
>>> STR="Hello World"
>>> type(STR)
<class 'str'>
>>> str.lower(STR)
'hello world'
>>> STR.lower() # str.xxx() == STR.xxx()
'hello world'
>>> STR[::-1] # 翻转字符串
'dlroW olleH'
>>> import string
>>> STR = "Hello {0}"
>>> f = string.Formatter()
>>> f.format(STR,"world")
'Hello world'
>>> STR.format("World")
'Hello World
- 字符串方法中检查前后缀:使用 .startswith()和.endswith()代替字符串切片
>>> STR[:5]=="Hello" # 切片 —— No!
True
>>> STR.startswith("Hello") # Yes!
True
- 使用 isinstance()代替对象类型的比较
if isinstance(obj, int): # Yes!
if type(obj) is type(1): # No!
- 判断序列(字符串、list、tuple)为空:
if not seq: # Yes!
if len(seq): # No!
- 不要用 == 进行布尔比较
if greeting: # Yes!
if greeting == True # No!
if greeting is True: # Worse
自动代码美化工具
要实现 PEP8 中的大部分条目并不难,但要持之以恒、实现所有条目,应该还是挺难的。
一个人要实现 PEP8 中的条目并不难,但要保证一个团队都做到,应该还是挺难的。
如果有一个自动代码美化工具,当我 Ctrl-S 保存文件的时候实时帮我按 PEP8 美化一下,上面 2 个问题就都不是问题了。
帮我们实现这个愿望有:
YAPF
$ pip install yapf
$ yapf [options] [files [files ...]]
常用的 options 有:
--diff: 输出 diff 文件,不修改源文件--style STYLE:- "pep8" or "google"
- 如果当前目录下有 .style.yapf 或 setup.cfg 文件,则从此文件中读取配置项
- 配置项有几十个,各人慢慢研究
.style.yapf 文件示例:
[yapf]
based_on_style = pep8
spaces_before_comment = 4
split_before_logical_operator = true
Black
![]()
用了 Black,相当于放弃了自己的编码风格,完全由 Black 来接手,一个团队的代码就像一个人写的 —— 至少样子上是。
经过一段时间之后,个人手写水平也能提高,逐步逼近 PEP8 的要求。
$ pip install black
$ black [options] [mypythonfile 或 dir]
常用的 options 有:
-t [py27|py33|py34|py35|py36|py37|py38]- Black 会自动逐个试探每个文件的 python 版本,应用不同的风格
--check:只检查,不修改源文件--diff: 输出 diff 文件,不修改源文件--include XXX,--exclude XXX: 操作目录时的筛选器
比较
| Item | YAPF | Black | 点评 |
|---|---|---|---|
| License | Apache2.0 | MIT | 两者都允许修改后闭源,即允许只发布二进制版本,但必须附带 License。 Apache 要求每个文件头上都要附带,MIT 只需要根目录下放一份即可。 |
| Author | Python | 所以 Black 只支持 PEP8,YAPF 则可定制 | |
| 创建日期 | 2015-03-18 | 2018-03-14 | 3 月是个好季节 |
| 提交次数 | 1000+ | 500+ | 截至 2019.5 |
| Github Star | 9k+ | 10k+ | 截至 2019.5 |
找一段代码实战比较一下,从左至右依次是:原始文件、black 处理后的文件、yapf 依 pep8 处理过的文件
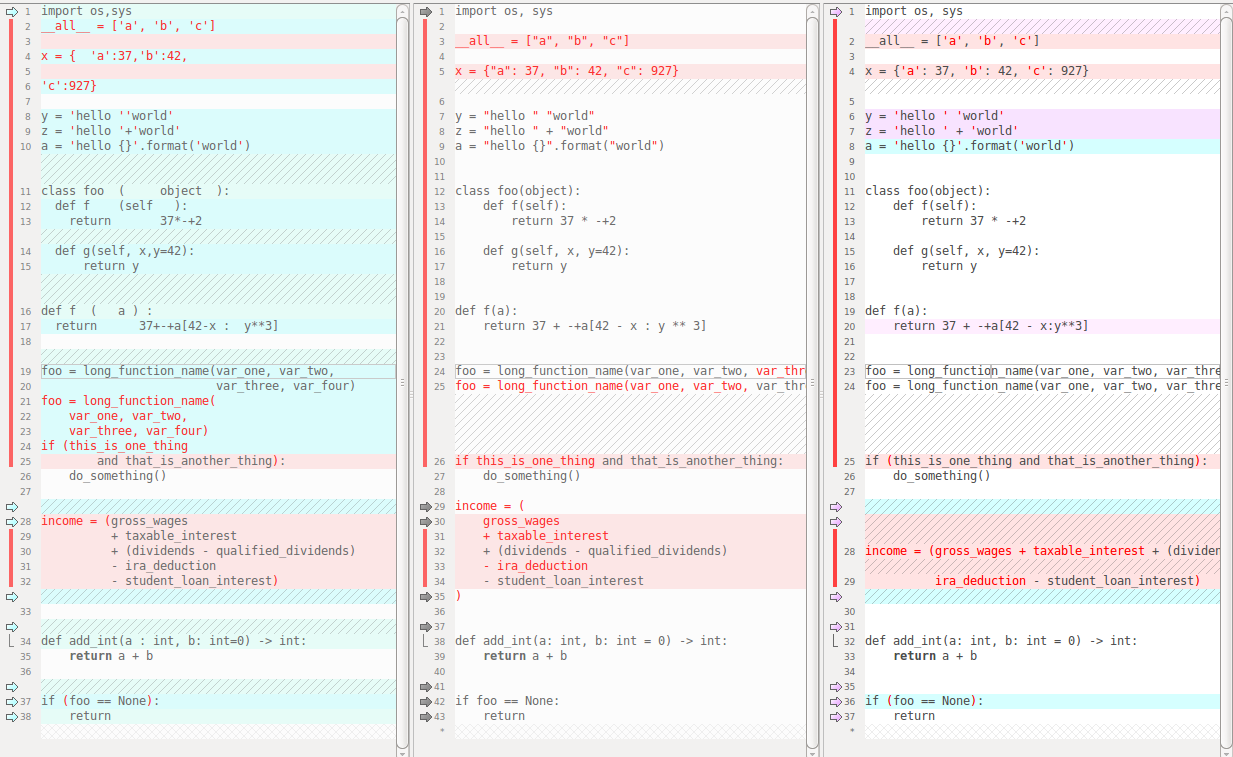
- 第 1 行:每次只 import1 个 model —— 没有帮我改过来
- 第 2 行:dunder 变量放置在 import 之前 —— 没有帮我改过来
- 第 9-18 行:空格、空行,black 和 yapf 都控制的不错
- 第 17 行:google 把索引中的冒号两边去掉了空格
- 第 19-23 行:因为没有超过 80 列,续行都合并到 1 行了
- 第 24-25 行:PEP8 中推荐的写法,black、yapf 都做了修正
- 第 28-32 行:PEP8 中推荐的写法,black 微调,yapf 大修 —— black 稍优
- 第 34 行:函数注释都能控制冒号左右的空格
- 第 37 行:要用 is 而不是==来比较 None —— 都没修改过来
可以看出 black 和 yapf 能做的和 PEP8 比较还是有限,且目前都还在书写美化上下功夫,在代码优化上不足。
合入 IDE
三层境界:
- 代码美化频率较低或非强制的客官,实现功能,再绑定个快捷键,就够用了。
- 成为粉丝后,想要强制执行美化,对自己毫不留情的客官,就需要捆绑到“文件保存(Ctrl-S)”时自动执行。
- 强迫症患者或脑残粉,需要边写边美化的客官,就有上一些监控手段,各大 IDE 也都为你准备好了 Watcher 伺候。
VSCode
VSCode 目前是我的主力 Editor,合入 VSCode 是刚需。
为 black 命令创建一个 VSCode 的 Task(下图中我命名为: beautifu my python code),F1--Run Task 的时候选中即可,如下图:
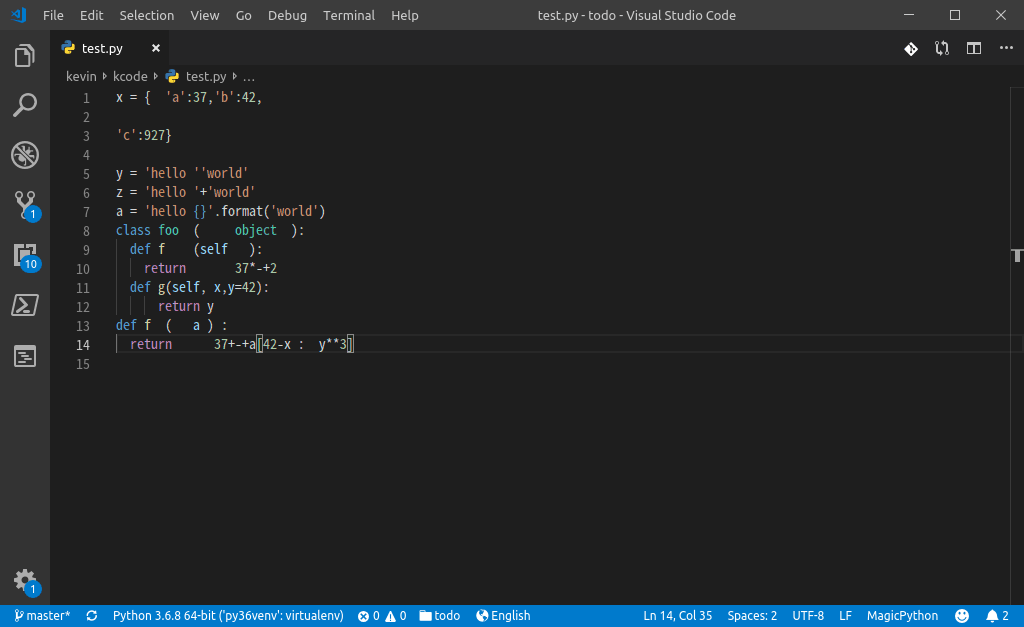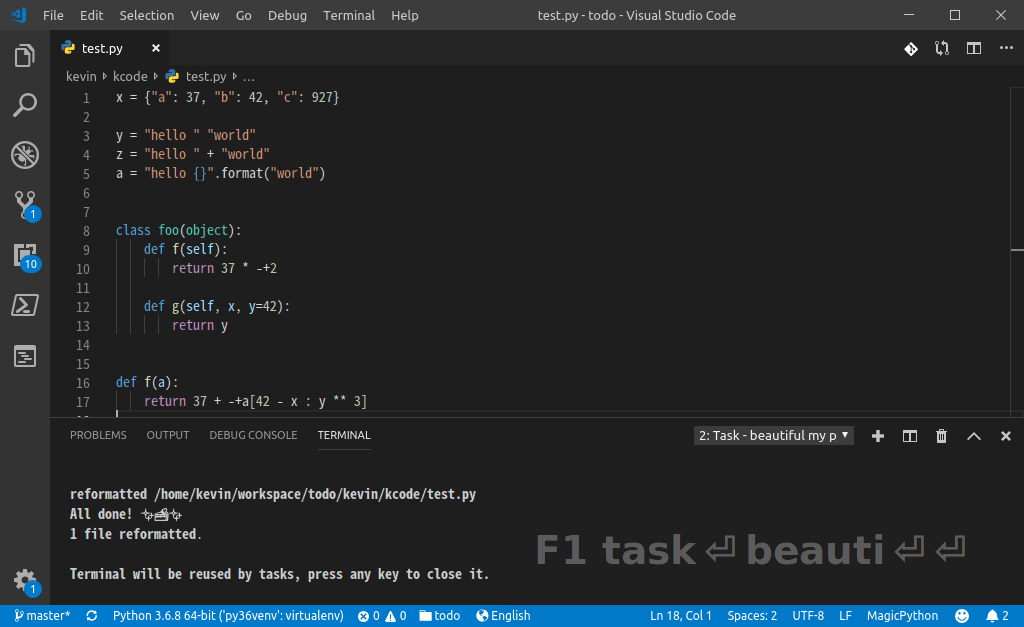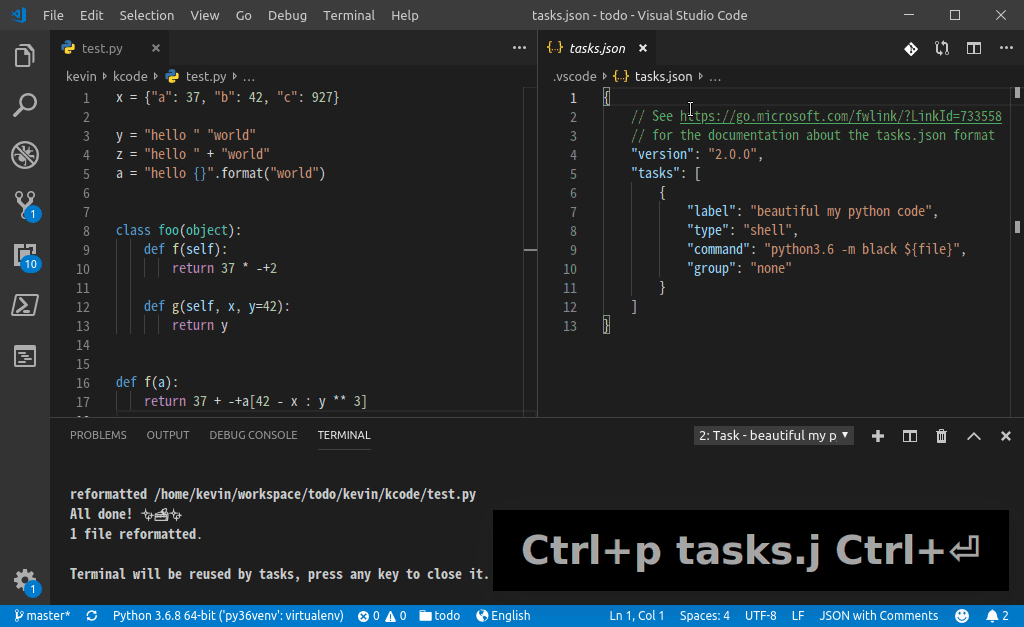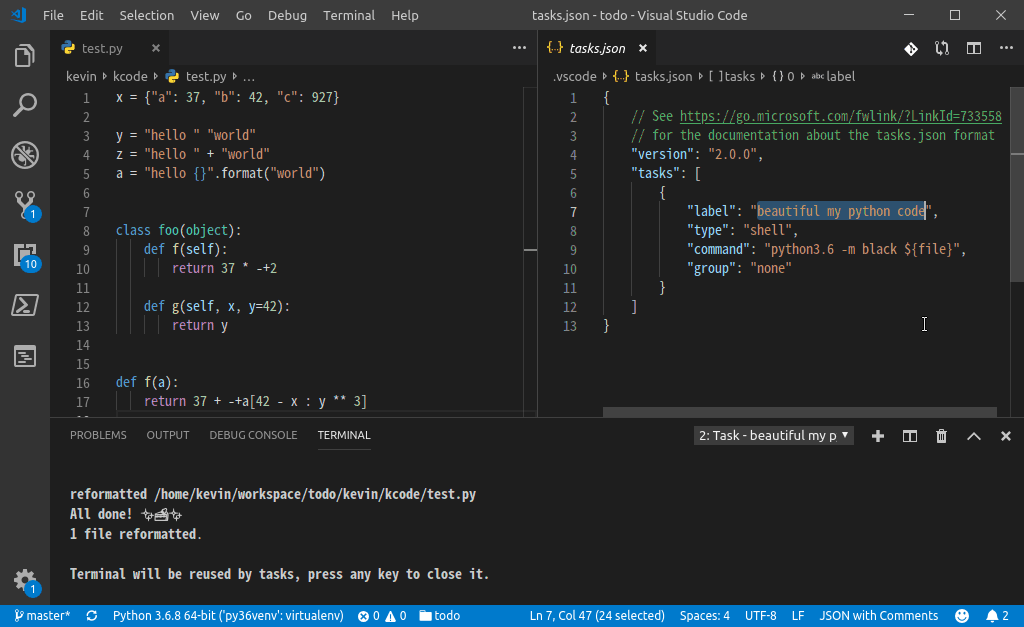
再绑定个快捷键就,爽快了:
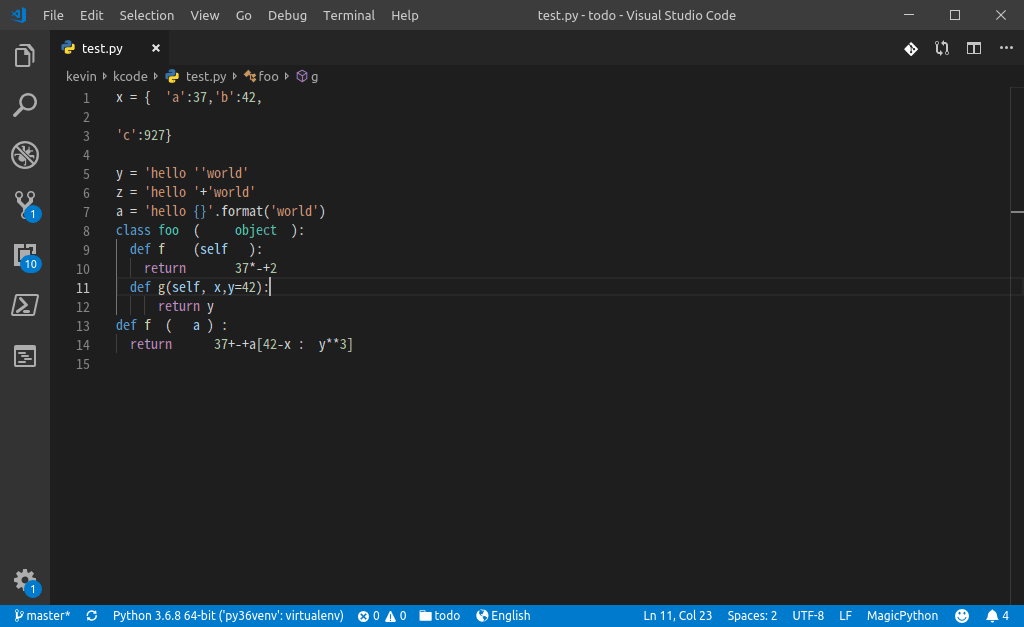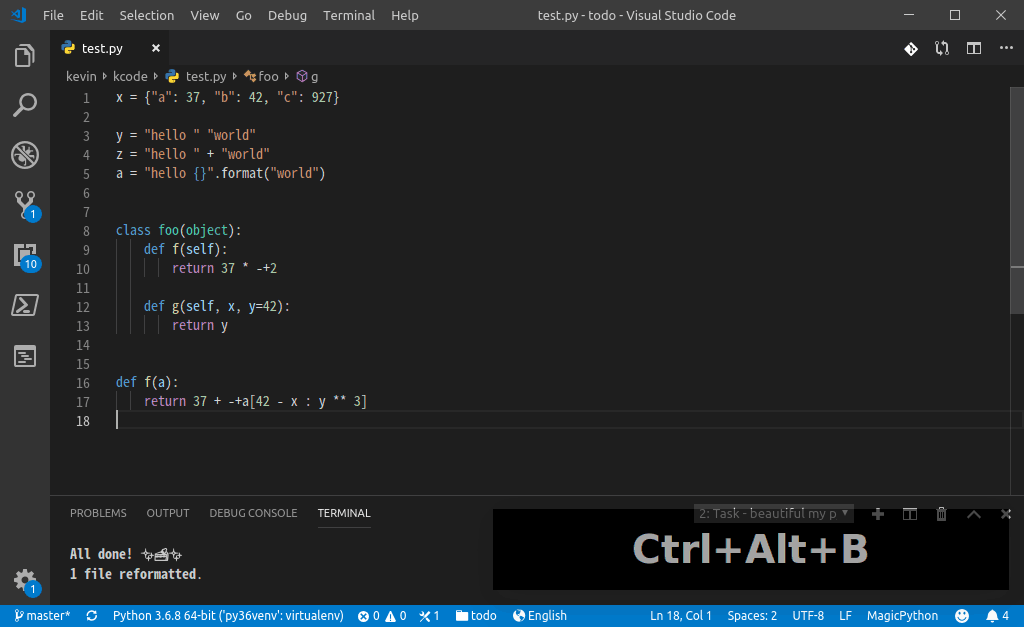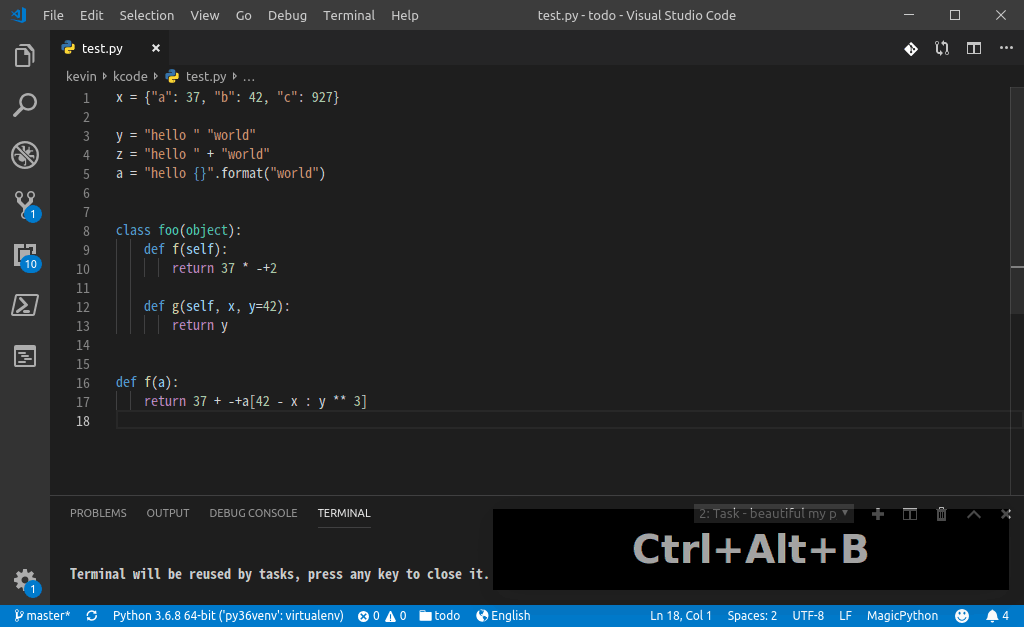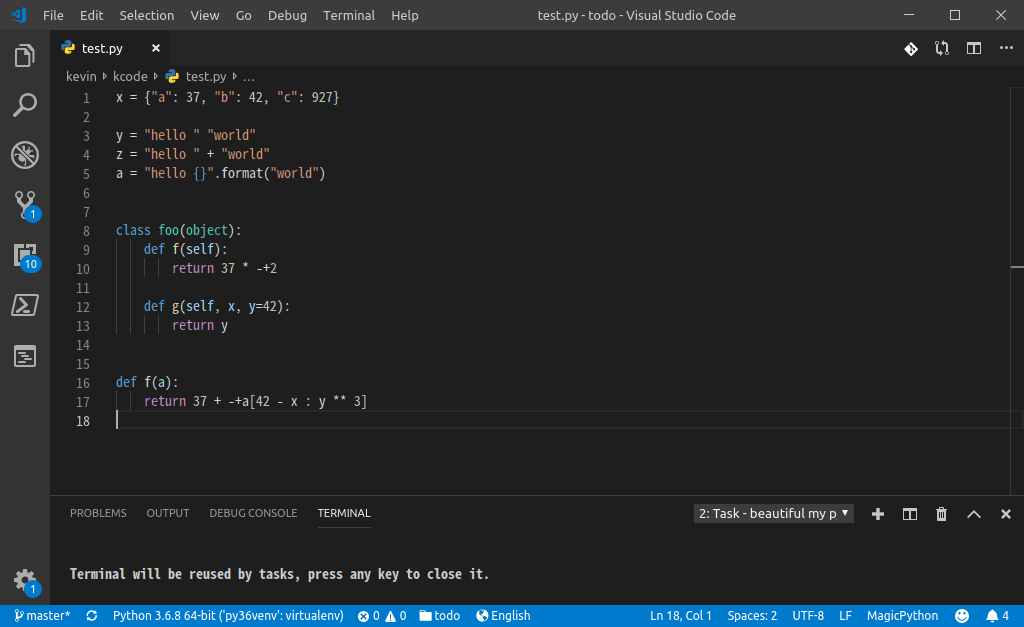
VSCode 可以将 Task 配置成 watching task,或使用 "run on save" 之类的 VSCode 扩展,可以实现“保存文件”或“其他动作”时自动执行美化 task。
PyCharm
PyCharm 的 Plugin 中可以搜到一个 black-pycharm 的插件,我试用了一下没玩转,还是自己配置吧。
首先在 Settings 中添加 External Tool:
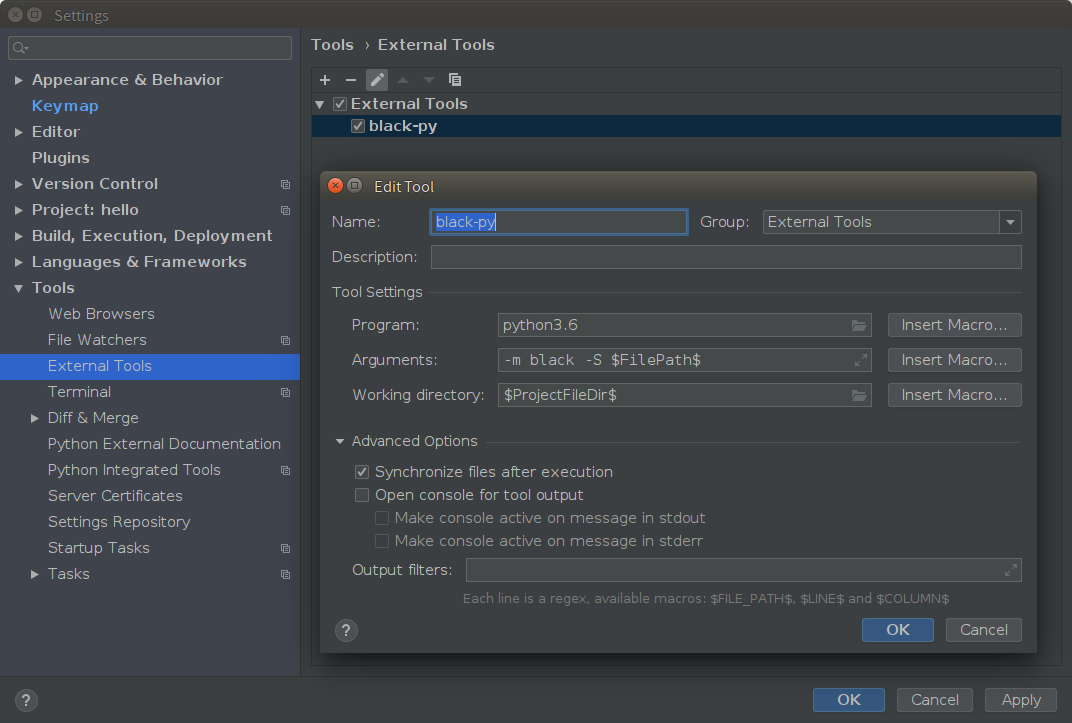
然后绑定到一个快捷键上:
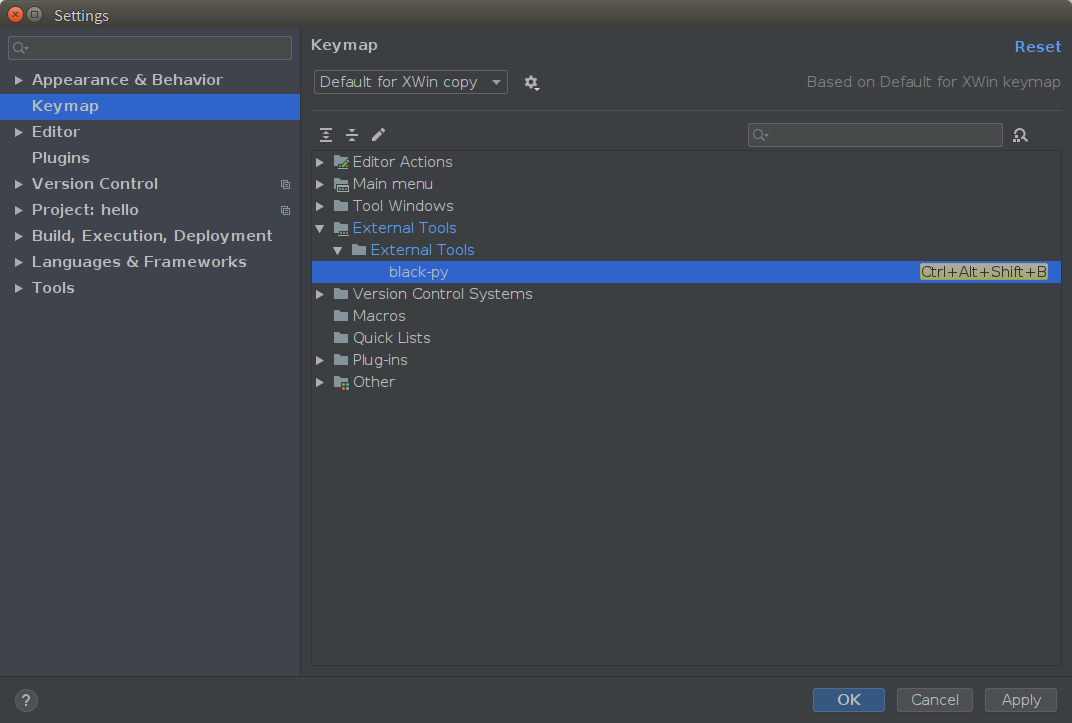
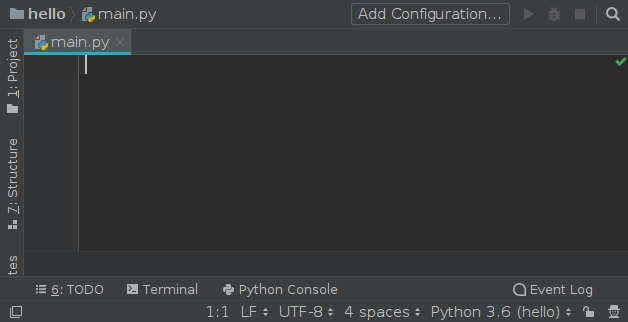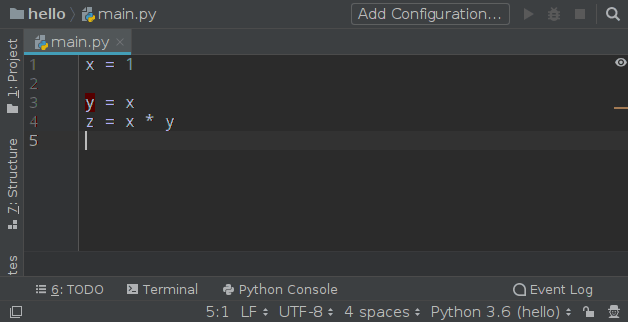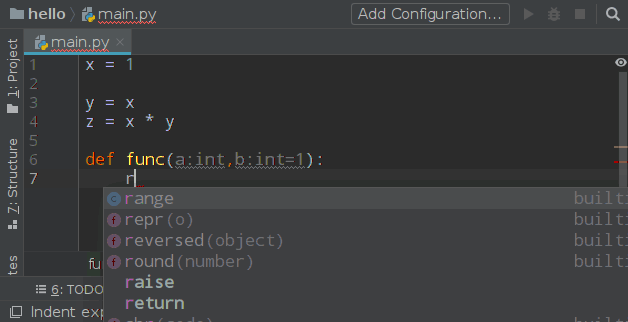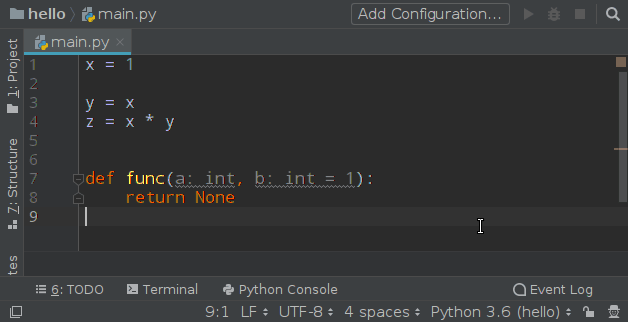
第 1 层境界练成!开始第 2 层:使用 pycharm 的一个 plugin: File Watcher 来实现,先添加插件,然后在 Tools 中添加一个 Watcher,如下图:
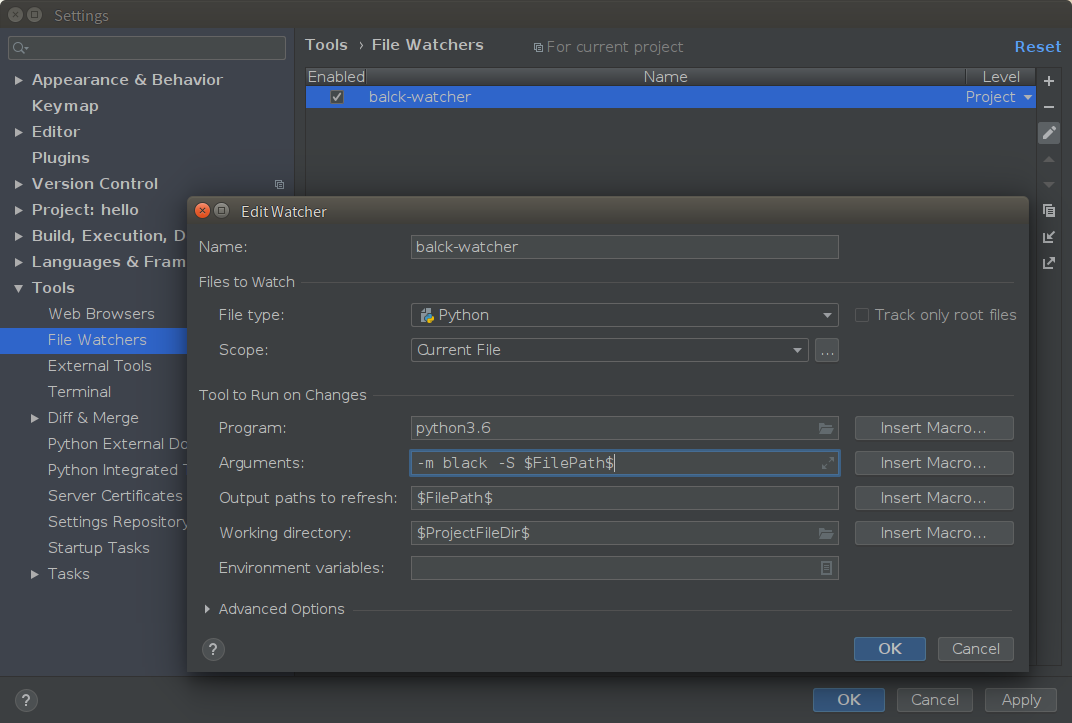
使用效果:
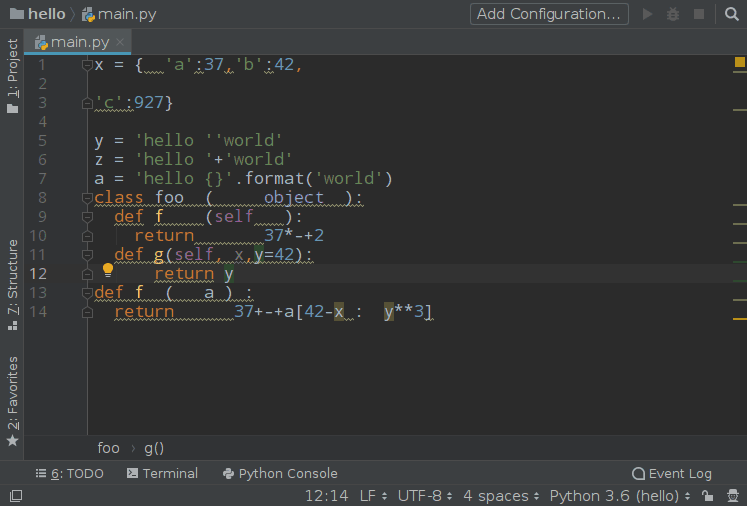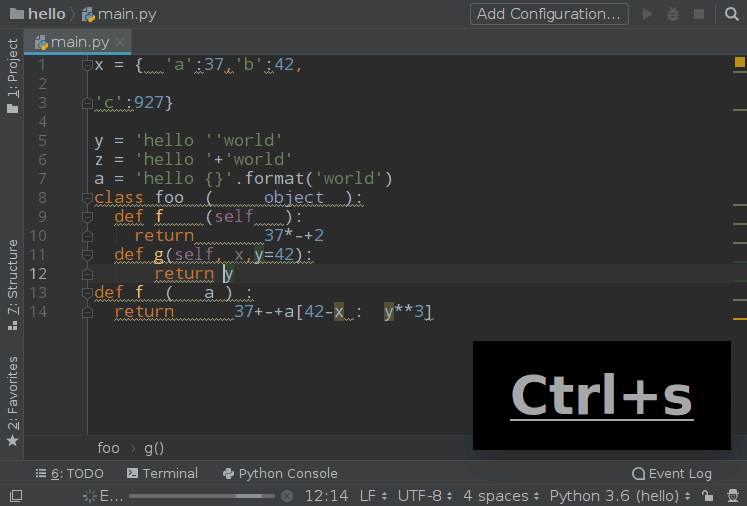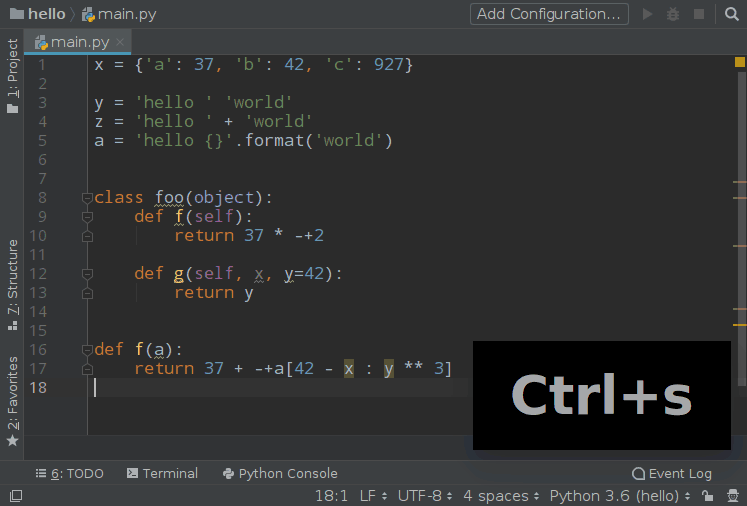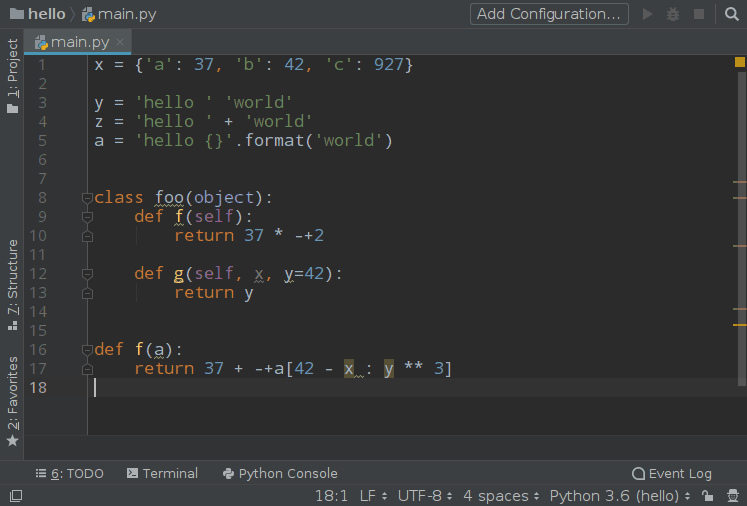
Watcher 的配置中有一个 Auto-Edit 的选项请不要勾选,否则你将会进入第 3 境界,这种感觉我试了一下,非常酸爽:
Good luck!