
我是从 3 月的 ChatGPT 爆发才开始关注大模型的,经过一番手忙脚乱的注册 openai 的 id、使用其 python sdk 后,这才开始转入对 LLM 的观察和学习上来。
2018 年学过 CNN、RNN 后除了在视觉上做了一些产品外,NLP 基本没接触,所以对 Transformer、ViT 都略过了,忽然被 ChatGPT 刺激了一下,才发现 Transformer 除了 NLP,也已经横扫 CV 了,效果超过 NN。那好吧,赶紧补课,把 LLM 学起来。
发展史
谢天谢地,有几篇 paper 已经准备好给我填鸭式教学了:
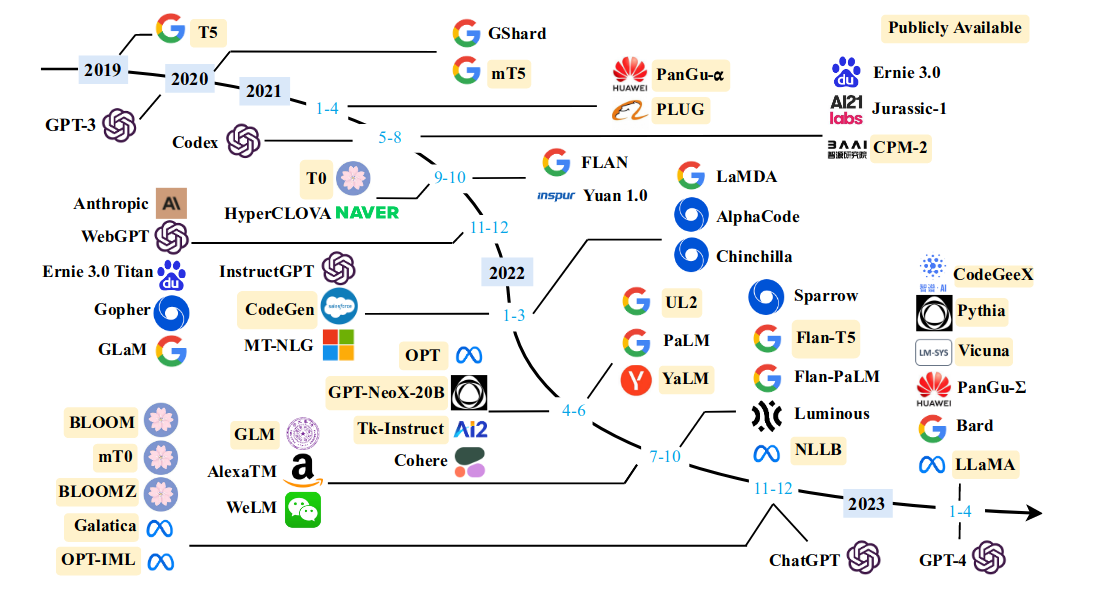
https://arxiv.org/abs/2303.18223 —— 首先是这篇一众国人联手写的,信息整理全面。挑了一些作为我后续关注的重点(重点关注国产、开源):
- 2018 OpenAI GPT
- 202103,THUDM(清华),GLM
- 202104,PLC(鹏程实验室)+华为,盘古
- 202105,OpenAI,CodeX
- 202205,THUNLP(OpenBMB),CPM
- 202302, Meta, LLaMA(羊驼),已经后续的 Alpaca(小羊驼)、Vicuna(野羊驼)
- 202303,THUDM(清华),CodeGeeX
后续补充:
- 202305,MosaicML, MPT
- 202305, bigcode(Huggingface & ServiceNow),StarCoder
读完 paper,基本了解了 LLM 的发展历程,比如:
- Transformer 从 2017.12 Google 提出后,经过了 3 年左右的缓慢爬坡,LLM 并没有大量出现,直到 2020 年,因为算力的提升,2020.5 英��伟达发布了 A100,单精度达到 19.5TFLOPS,助力了 LLM 开始狂飙。
- ChatGPT 是 GPT-3 之后的 InstructGPT 改造而来的。
- THUDM 和 THUNLP 分别是清华计算机学院和 NLP 学院的两个团队,分别打造 LLM。
- Google 发布的 LLM 可谓是最多,但没能创造风口,有点遗憾。后来读到 2022.02 Google 的《LaMDA: Language models for dialog applications》(http://arxiv.org/abs/2201.08239),可以看到 Google 诉苦良多,为了 Quality、Safety、and Groundedness,让 OpenAI 占了先机,气的很,哈哈。
- 了解到 LLM 考虑到本地 inference 受限,大多以是所有 WebAPI 作为使用接口(ChatGPT 就是这样)。
- 了解到各个模型根据语料库的不同,在不同领域表现不同,所以拿 GPT-3 与 AlphaCode 比谁生成的代码好就不厚道了,因为 GPT-3 的数据集里没有 Code。
总之,很感谢作者们的这篇文章,让我有了个全貌的了解。
第 2 篇:https://arxiv.org/abs/2304.13712 —— 这篇文章更学术一些,amazone 一众研究员撰写,开篇一幅图就爱了:
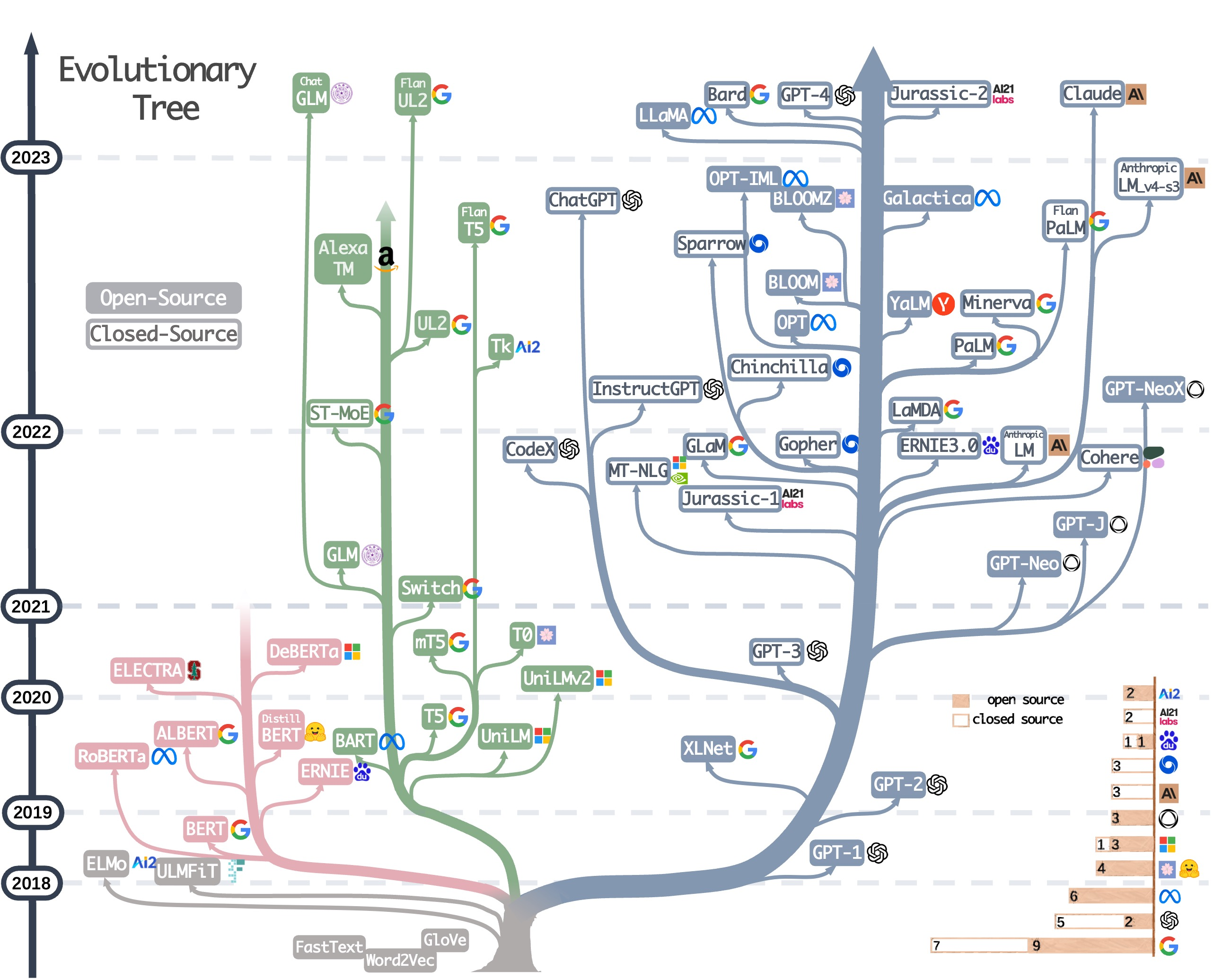
它根据 Encoder、Decoder、Encoder&Decoder 三个分支给 LLM 做了分类,当然这不是什么新分类法,Huggingface 中的文档 The Transformer model family 早就是这么分�类的了,但这个图画的确实好,整理的很完整,我甚至打印出来,没遇到一个最近发布的新模型,还要定位、补充进去。
领域视角
最颠覆的我的,就是看到 ViT,看了 An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale,再听了李沐在 Bilibili 上解读 ViT 的视频后,更加对 Transformer 兴趣盎然,后来又进一步了解到凯明大神的 MAE,以及 Diffusion 扩散模型、DiTs……好多东西扑面而来,虽然我无法弄懂里面的所有原理,但尽可能的理解对于开发基于 LLM 的 APP 应该是有益的。
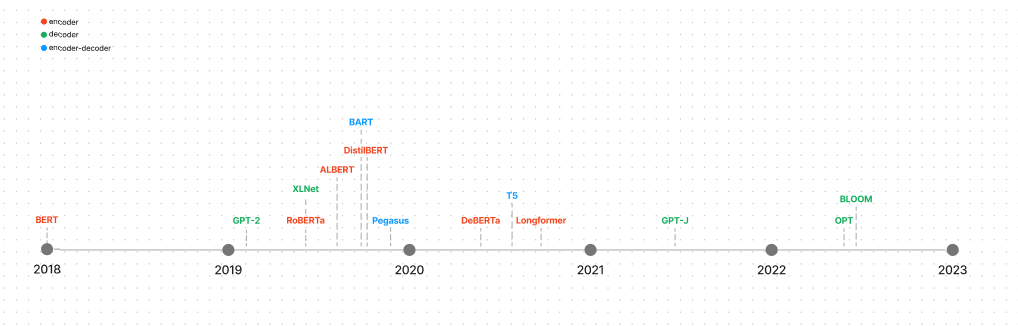
下面分别是 Transformer 模型在 NLP、视觉、Audio、多模态 四个领域的主流模型,图中并不是某某公司发布的 LLM,而是 LLM 的技术架构,分成四幅图很好的展示了四个应用领域(或场景)。
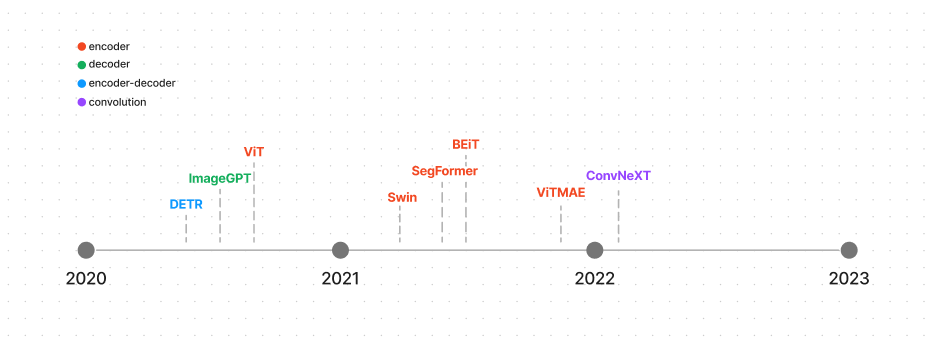
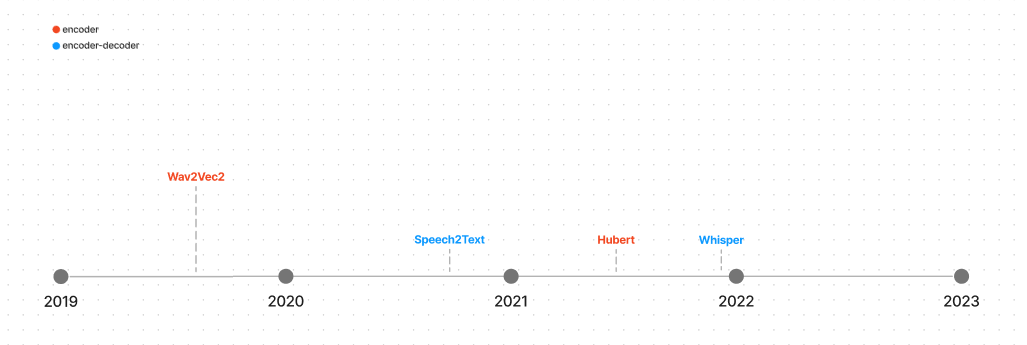
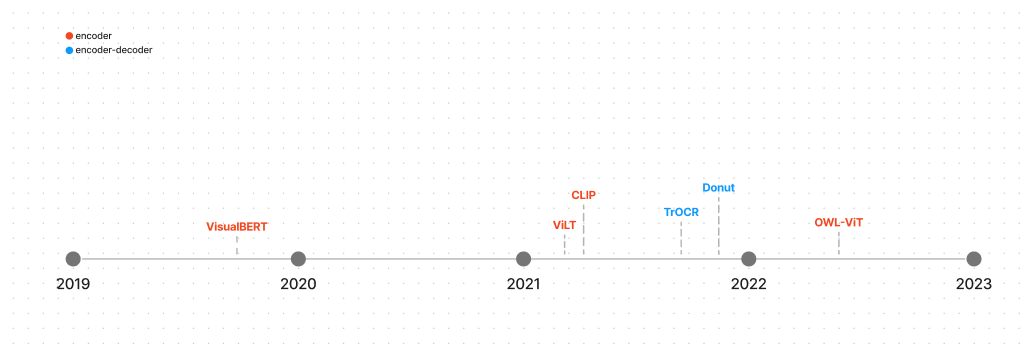
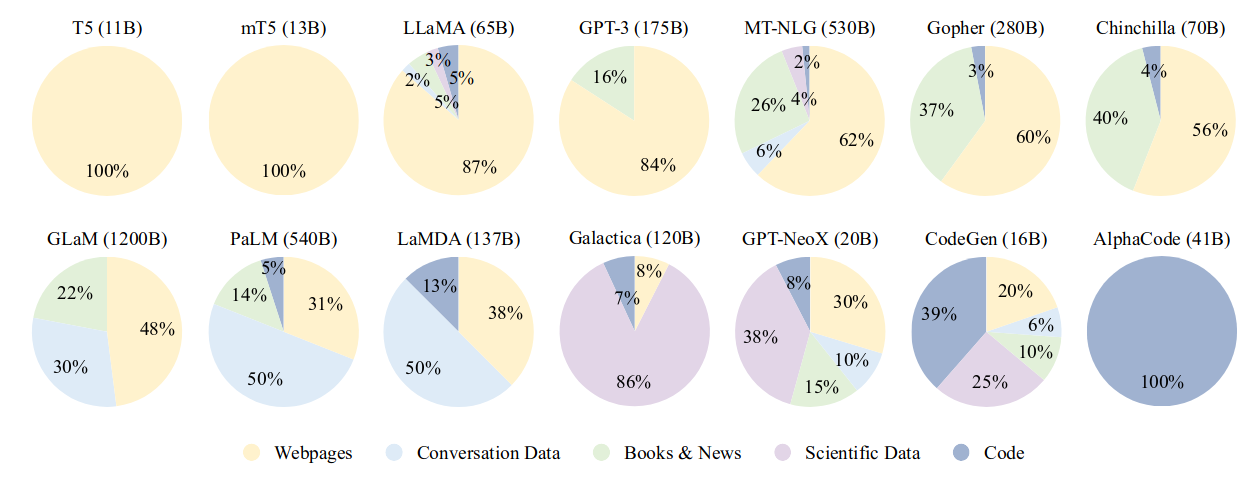
成本
大型语言模型在尺��寸和成本上都在不断扩大。2019 年发布的 GPT-2 被认为是第一个大型语言模型,它有 1.5B(15 亿)个参数,训练成本估计为 5 万美元。仅仅三年后,540B 参数,预估花费 800 万美元的 Palm 就出来了。 2022 年末至今,在所有领域,大型语言和多模态模型都在变得更大、更贵。2023 年 4 月斯坦福发布的 《The State of AI in 2023》中显示:
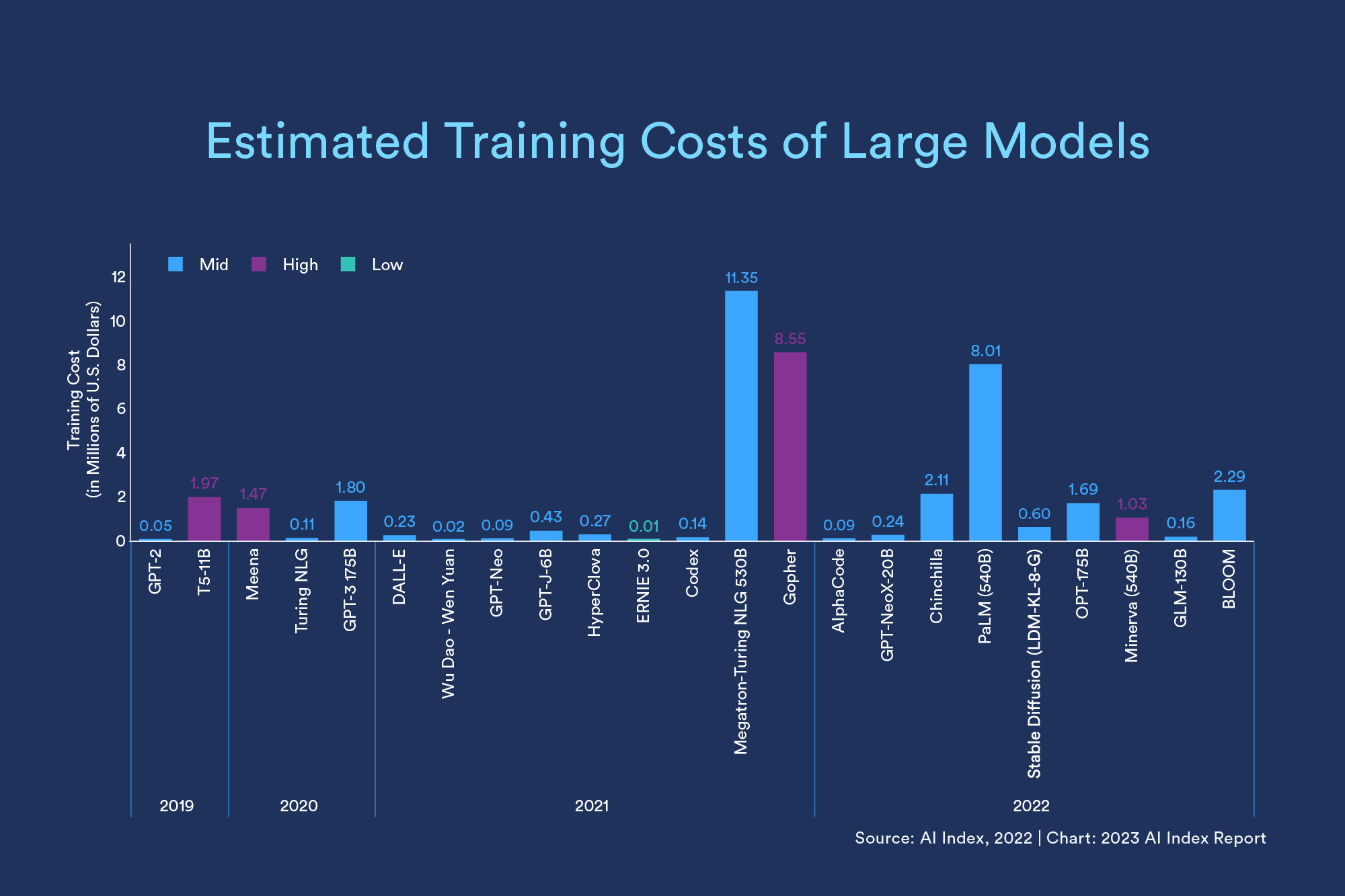
有些 LLM 还会在自己的网站上写明花费,比如清华 THUNLP 的 OpenBMB 社区的 CPM:43w,68 天 —— 你觉得这钱和这碳排放值不值?
Task
LLM 能做什么?怎么分类?
可能很多人和我一样,从 ChatGPT 切入 LLM 后对它聊天之外的能力感觉不明显,但聊天是我们口语话的功能,并不是技术领域的 Task,比如聊天中可能需要总结一段话、预测下一句、填空、回答一个指定问题、翻译……这都是聊天,那专业的分类方式是什么,看这里:
列了 27 个 Task
- audio
- "audio-classification"
- "automatic-speech-recognition"
- "zero-shot-audio-classification"
- cv
- 分类
- "image-classification"
- "video-classification"
- "zero-shot-image-classification"
- 物体检测
- "object-detection"
- "zero-shot-object-detection"
- 分割
- "image-segmentation"
- 深度估算
- "depth-estimation"
- 分类
- nlp
- 文本分类
- "text-classification" (alias "sentiment-analysis" available)
- "zero-shot-classification"
- token 分类
- "token-classification"
- 问答
- "question-answering"
- "table-question-answering"
- 总结
- "summarization"
- 翻译
- "translation"
- "translation_xx_to_yy"
- 语言建模(生成)
- "text2text-generation"
- "text-generation"
- "fill-mask"
- "mask-generation"
- "conversational"
- 文本分类
- 多模态
- "document-question-answering"
- "feature-extraction"
- "image-to-text"
- "visual-question-answering"
先建立这些概念,这样当开发 LLM 的 API 时,就可以轻松地使用 SDK 中的各种 API 及其术语、概念。
playground
虽然已经出现了一些笔记本可运行的大模型,甚至浏览器可以运行的 LLM,但主流还是在有 GPU 的电脑、工作站上运行的模式,当然最好是薅一些 Data Center 的羊毛,比如:
- HuggingFace 上的 space 可以用 hf 的算力,来运行一些 hf 的 model,各个 model 呈现的 UI 不一样,需要仔细挑选一下。
- OpenAI playground: OpenAI 为 ChatGPT(其实包括了 GPT 多个版本)开发的演练场,可以在里面玩一玩,对应学习 openai 的 python sdk 包是有帮助的。